Das Daidalos-Projekt erforscht das Potential digitaler Forschungsmethoden für aktuelle Forschungsfragen der Klassischen Philologie. Dabei liegt der Fokus auf Methoden des Natural Language Processing (NLP). Das Projekt vereint ausgewählte Forschungswerkzeuge, autodidaktische Weiterbildungsbausteine und eine Anlaufstelle für Forschende der Klassischen Philologie in einer webbasierten Forschungsinfrastruktur.
Mittelgeber: DFG
Förderbereich: Wissenschaftliche Literaturversorgungs- und Informationssysteme (LIS)
Programm: e-Research-Technologien
Projektnummer: 518919950
Daidalos
Entwicklung einer Infrastruktur zum Einsatz von Natural Language Processing (NLP) für Forschende der Klassischen Philologie
Die Digitalisierung macht auch vor der Klassischen Philologie nicht Halt. Bis vor einigen Jahrzehnten blieb den Forschenden nichts Anderes übrig, als sich in mühevoller Handarbeit einen Weg durch ihre Texte zu bahnen. Obwohl diese Arbeitsweise beeindruckende und mustergültige Werke hervorbrachte, haben heute verfügbare digitale Forschungswerkzeuge das Potential, entscheidende Arbeitsschritte zeitsparender und weniger fehleranfällig zu erledigen.
Daidalos ist keinesfalls das erste klassisch-philologische Projekt mit einem Fokus auf digitale Forschungsmethoden. Sein Alleinstellungsmerkmal besteht zum einen darin, dass es versucht, existierende digitale Methoden der Textanalyse und der Ergebnisdarstellung in einer webbasierten Forschungsinfrastruktur zu vereinigen, diese auch für Projektexterne evidenzbasiert und nachvollziehbar zu evaluieren und weiterzuentwickeln. Zum anderen versteht sich Daidalos als Kontaktpunkt für interessierte Forschende (Community of Practice) und als Lernort, an dem Forschende ihre digitale Kompetenz (Digital Literacy) mithilfe verschiedener Lernbausteine autodidaktisch auf- und ausbauen können.
Bedarfsorientierung durch Forschungstandems
Für eine begründete Auswahl der von Daidalos angebotenen Textkorpora, Analysewerkzeuge, Visualisierungen und Lernbausteine evaluiert das Projekt-Team zunächst das Potential ausgewählter NLP-Methoden. Dies geschieht auf Grundlage von realen Forschungsfragen (z. B. zu Autorschaft, Intertextualität oder Diskursstrategien), die aus der Forschungsgemeinschaft an das Daidalos-Projekt herangetragen werden. Die Zusammenarbeit in diesen Forschungstandems ist wie folgt angelegt: In einem ersten Beratungsgespräch präsentieren die Forschenden ihr Forschungsinteresse, eine mögliche Forschungsfrage und das gewünschte Textkorpus. Das Daidalos-Team berät sie bei der Konkretisierung der Forschungsfrage und erklärt, welche Analysewerkzeuge (z. B. morphosyntaktische Tagger, Arbeit mit Word Embeddings) und Visualisierungsoptionen (z.B. annotierter Text, Graph) geeignet sein könnten. Die von Daidalos angebotenen Werkzeuge der maschinellen Sprachverarbeitung ermöglichen sowohl die Analyse linguistischer Erscheinungen (u. a. Wortarten, Kollokationen, Syntax) als auch literaturwissenschaftlicher Fragestellungen (u. a. Genremerkmale, Paraphrasensuche, antike Konzepte). Sobald die Analyseergebnisse vorliegen, übergibt das Daidalos-Team sie den Forschenden zur Beurteilung. In einem weiteren Gespräch evaluieren die Forschenden gemeinsam mit dem Daidalos-Team die Qualität der Ergebnisse und der Visualisierung. Bei Bedarf werden die Parameter angepasst und weitere Analysedurchgänge durchgeführt. Die aus den Forschungstandems gewonnen Erkenntnisse werden als Use Cases zum Aufbau der webbasierten Infrastruktur und zur Gestaltung der Lerneinheiten genutzt.
Interaktive Forschungsinfrastruktur als Lernangebot
Der interaktive Zugang zu antiken Texten soll nicht nur Forschungsfragen beantworten helfen, sondern auch Methodenreflexion fördern und User qualifizieren. Entsprechend bietet die Software folgende Inhalte:
a) Demo-Workflows mit konfigurierbaren Elementen, z. B. Korpusauswahl, wobei die Konfiguration mittels kuratierter, authentischer Beispiele detailliert erklärt und reflektiert wird;
b) eine domänenspezifische Oberfläche u. a. mit Interaktionen zu Forschungsinteresse und Methodenwahl; Speicherung von personalisierten Einstellungen; Übungen und Code-Snippets in Jupyter Notebooks;
c) freie Konfiguration von Text- und Methodentriangulation, Einbindung von eigenem Quellcode für erfahrene Forschende.
Daidalos
Development of an infrastructure for the use of natural language processing (NLP) for researchers in the field of Classics
Classical philology is undergoing a process of digitisation. Until a few decades ago, researchers had no choice but to make their way through their texts by hand. Although this way of working produced impressive and exemplary results, the digital research tools available today have the potential to save time and minimise the risk of errors. Daidalos is by no means the first Classics project to focus on digital research methods. Its unique selling point is that it attempts to combine existing digital methods of text analysis and visualisation in a web-based research infrastructure. It also seeks to evaluate and further develop these methods in an evidence-based and easily comprehensible way. Daidalos aims to be a platform for interested researchers (community of practice) and a learning environment where researchers can develop and expand their digital skills (digital literacy) with the help of various autodidactic learning modules.
Tailoring to needs of users through research teams (tandems)
To make an informed selection of the text corpora, analysis tools, methods of visualisation and learning modules offered by Daidalos, the first step for the project team is to evaluate the potential of selected NLP methods. This is done on the basis of real research questions (e.g. on authorship, intertextuality or discourse strategies) that are presented to the Daidalos project by members of the research community. Collaboration in these research tandems is organised as follows: In an initial consultation, the researchers present their research interest, a possible research question and the desired text corpus. The Daidalos team advises them on the specifics of the research question and explains which analysis tools (e.g. morphosyntactic taggers, working with word embeddings) and visualisation options (e.g. annotated text, graph) might be suitable. The machine language processing tools offered by Daidalos make it possible to analyse both linguistic phenomena (e.g. word types, collocations, syntax) and literary questions (e.g. genre features, paraphrase search, ancient concepts). As soon as the results of the analyses are available, the Daidalos team hands them over to the researchers for assessment. In a follow-up meeting, the researchers evaluate the quality of the results and the visualisation together with the Daidalos team. If necessary, the parameters are adjusted and further analyses are carried out. The insights gained from these use cases are channelled into the development of the website infrastructure and the design of the training material.
Interactive research infrastructure as a learning offer
The interactive access to ancient texts is not only intended to help answer research questions, but also to promote methodological reflection and empower users. Accordingly, the software offers the following content:
(a) Demo-workflows with configurable elements, e.g. corpus selection, with detailed explanations;
(b) a domain-specific interface with various features including interactions on research interest and method selection; storage of personalised settings; exercises and code snippets in Jupyter Notebooks;
(c) free configuration of text and method triangulation, integration of own source code for experienced users.
Principle Investigators
 |  |  |
| Prof. Dr. Anke Lüdeling | Direktor Malte Dreyer | Dr. Andrea Beyer |
| Korpuslinguistik | Computer- und Medienservice | Klassische Philologie |
Wissenschaftliche Mitarbeiter
 |  |  |
| Nico Faltin | Konstantin Schulz | Florian Kotschka |
| Latinist | NLP-Spezialist | Softwarearchitekt |
Studentischer Mitarbeiter
 |
| Florian Deichsler |
| Historischer Linguist |
Forschungsbeispiele
Beispiel 1
Mit welchen Attributen ist bellum verknüpft? Ist die Kollokation bellum iustum als Konzept nachweisbar?
(vgl. Girardet, Klaus M. "Gerechter Krieg - Von Ciceros Konzept des Bellum Iustum bis zur UNO-Charta." In Res Publica und Demokratie, herausgegeben von Helmut König, Emanuel Richter und Rüdiger Voigt, 191-223. Baden-Baden: Nomos, 2007).
Mit Daidalos könnte man die Kontexte, in denen das Wort bellum vorkommt, auf ihre Assoziationsstärke hin untersuchen. Die Assoziationsstärke gibt an, wie häufig bestimmte Wörter gemeinsam auftreten. (Abb. 1).

Beispiel 2
Wie wird mit Faktualität (Gegensatzpaar: fabula - probata, "bloße Erzählung - überprüfte Fakten") in verschiedenen Gattungen umgegangen?
(vgl. Cordes, Lisa. "Wenn Fiktionen Fakten schaffen. Faktuales und fiktionales Erzählen in den spätantiken Panegyrici Latini." In Faktuales und fiktionales Erzählen II. Geschichte - Medien - Praktiken,herausgegeben von Dustin Breitenwischer, Hanna-Myriam Häger und Julian Menninger, 31-56. Baden-Baden: Ergon, 2020)
Daidalos könnte die Suche relevanter und oftmals unerwarteter Textstellen unterstützen, indem die Software mittels distributioneller Semantik die Suche nach Wortfeldern, Themen oder ähnlichen Diskursstrukturen ermöglicht (Abb. 2).

Nachgenutzte Software und Datensätze
| Beschreibung | Lizenz | Herkunft |
|---|---|---|
| Altgriechische und Lateinische Stoppwortlisten | CC BY NC SA | Berra, Aurel. Ancient Greek and Latin Stopwords [Data set]. https://github.com/aurelberra/stopwords. |
| Altgriechisches KI-Modell für Named Entity Recognition (UGARIT/flair_grc_bert_ner) | CC BY 4.0 | Yousef, Tariq, Palladino, Chiara und Jänicke, Stefan. “Transformer-Based Named Entity Recognition for Ancient Greek.” In Digital Humanities 2023: Book of Abstracts, herausgegeben von Anne Baillot, Toma Tasovac, Walter Scholger und Georg Vogeler, 420-2. Zenodo, 2023. https://doi.org/10.5281/zenodo.8107629. |
| Altgriechisches KI-Modell für Sprachverarbeitung (greCy) | MIT | Myerston, Jacobo und López, Jose. greCy: Ancient Greek spaCy Models for Natural Language Processing in Python (Version 1.0) [Computer software]. https://github.com/jmyerston/greCy. |
| Korpussuch- und Visualisierungswerkzeug (graphANNIS) | Apache-2.0 | Krause, Thomas. graphANNIS. Zenodo, 2024. https://doi.org/10.5281/zenodo.2598164. |
| Software für Topic Modelling und Textvektorisierung (Gensim) | LGPL-2.1 | Řehůřek, Radim und Sojaka, Petr. "Software Framework for Topic Modelling with Large Corpora." In Proceedings of LREC 2010 workshop New Challenges for NLP Frameworks, herausgegeben von René Witte, Hamish Cunningham, Jon Patrick, Elena Beisswanger, Ekaterina Buyko, Udo Hahn, Karin Verspoor und Anni R. Coden, 46-50. Malta: ELRA, 2010. http://is.muni.cz/publication/884893/en. |
Aktueller Stand der maschinellen Sprachverarbeitung für Latein und Altgriechisch
Was ist momentan grundsätzlich möglich?
Die aktuellen Möglichkeiten der maschinellen Sprachverarbeitung für Latein und Altgriechisch erlauben es uns beispielsweise,
- Informationslücken in historiografischen Texten zu finden, indem wir Personen, Orte und andere Eigennamen erkennen.
- die Rolle der Polis in Epitaphien zu untersuchen, indem wir
- Wörter und Textstellen thematisch durchsuchen und gruppieren und
- moralisch positive und negative Narrative identifizieren.
- die Imitation des Ciceronischen Stils in neuzeitlichen Aufsätzen nachzuweisen, indem wir
- den Satzbau analysieren, z.B. Subjekte, Objekte, Prädikate,
- Wortarten erkennen,
- morphologische Informationen erkennen, z.B. Kasus, Numerus, Genus, Tempus, Modus.
Fehleranfälligkeit
Die maschinelle Sprachverarbeitung befindet sich in stetiger Weiterentwicklung. Systeme zur automatischen Analyse antiker Sprachen sind nie perfekt, machen also Fehler. Ein Beispiel ist die Lemmatisierung, wo flektierten Wörtern mitunter die falsche Grundform zugeordnet wird.
Geschwindigkeit der Weiterentwicklung
Dennoch wird die Leistung der Algorithmen tendenziell immer besser, d.h. sie machen ihre Arbeit schneller und zuverlässiger. Darum lohnt es sich, den Stand der Dinge im Blick zu behalten und regelmäßig neu zu evaluieren. Selbst wenn die Ergebnisse in einem bestimmten Fall noch nicht unseren Ansprüchen genügen, kann dies schon wenige Jahre später ganz anders aussehen.
Notwendigkeit der Fortbildung
Solange wir also mit solchen Algorithmen arbeiten, sollten wir uns regelmäßig fortbilden:
- Welche neuen Veröffentlichungen zum Thema gibt es?
- Wie funktionieren die neuen Algorithmen und Methoden?
- Was wird wahrscheinlich demnächst möglich sein?
Zum Nachlesen
Berti, Monica, ed. Digital Classical Philology: Ancient Greek and Latin in the Digital Revolution. Berlin: De Gruyter, 2019.
Johnson, Kyle P., Burns, Patrick J., Stewart, John, Cook, Todd G., Besnier, Clément und Mattingly, William J.B. “The Classical Language Toolkit: An NLP Framework for Pre-Modern Languages.” In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing: System Demonstrations. Association for Computational Linguistics, herausgegeben von Heng Ji, Jong C. Park und Rui Xia, 20–9. Association for Computational Linguistics, 2021. PDF
Revellio, Marie. Classics and the Digital Age: Advantages and Limitations of Digital Text Analysis in Classical Philology. Digital Humanities Cooperation, 2015. PDF
Short, William. Blog: Computational Classics? Programming Natural Language Understanding. Society for Classical Studies Blog, 2019. PDF
Sommerschield, Thea, Assael, Yannis, Pavlopoulos, John, Stefanak, Vanessa, Senior, Andrew, Dyer, Chris, Bodel, John, Prag, Jonathan, Androutsopoulos, Ion, und de Freitas, Nando. “Machine Learning for Ancient Languages: A Survey.” Computational Linguistics 49, no. 3 (September 2023): 703–47.
Community of Practice
Im Rahmen des Daidalos-Projektes haben wir den überregionalen Arbeitskreis Digital Classics (BridgeClassics) aufgebaut, den wir zu einer Community of Practice (CoP) im Sinne des situierten Lernens (Lave und Wenger, Situated Learning) erweitern und mit DH-Workshops unterstützen.
Erfolgskriterien für eine CoP sind „leadership roles, personalized learning, guiding principles, organizational support, social learning and purpose“ (Trust und Horrocks, "Six Key Elements," 108)
Die CoP wird durch Forschungstandems ausgebaut, wie sie u. a. im Design-Based Research Ansatz (Bakker, Design Research) üblich und auch in unserer Fachcommunity (Freund und Jannsen, "Forschendes Lernen") bekannt sind.
Bakker, Arthur. Design Research in Education: A Practical Guide for Early Career Researcher. New York: Routledge, 2018.
Freund, Stefan und Janssen, Leoni. "Forschendes Lernen im Praxissemester unter den Bedingnungen kleiner Fächer. Ein Praxiskonzept für die Begleitung von Studienprojekten im Praxissemester am Beispiel des Faches Latein." Die Materialwerkstatt. Zeitschrift für Konzepte Und Arbeitsmaterialien für Lehrer*innenbildung Und Unterricht 2 no. 2 (2020): 66–74.
Lave, Jean und Wenger, Etienne. Situated Learning: Legitimate Peripheral Participation. Cambridge: Cambridge University Press, 1991.
Trust, Torrey und Horrocks, Brian. "Six Key Elements Identified in an Active and Thriving Blended Community of Practice." TechTrends 63, no. 2 (2019): 108-15.

Forschungstandems
Der Aufbau der Daidalos-Infrastruktur erfolgt u.a. über sogenannte Forschungstandems. Dabei handelt sich um Kollaborationen mit einigen Forschenden, die ihre Forschungsfrage mit Bitte um Mithilfe an das Daidalos-Team herangetragen haben. Gemeinsam werden Bedarfe herausgearbeitet und mögliche NLP-Lösungen besprochen und umgesetzt. Der idealtypische Ablauf eines Forschungstandems sieht wie folgt aus:
- Erster Kontakt
- Erstgespräch Forschungsfrage, Korpus, NLP-Methoden
- Bereitstellung Forschungsmaterial
- Prototyp, erste Ergebnisse
- Zweitgespräch Ergebnisdiskussion
- ggf. Iteration 3-5
- Kooperative Publikation
Wir möchten Sie sehr herzlich zu unserem ersten Workshop einladen, mit dem wir unser DFG-Projekt Daidalos offiziell der interessierten Fachcommunity vorstellen und zum Mitmachen anregen wollen.

| Programmpunkt | Uhrzeit | Speaker |
|---|---|---|
| Anmeldung | 08:30 Uhr | |
| Begrüßung, Vorstellung des Daidalos-Projektes | 09:00 - 09:15 Uhr | Prof. Dr. Lisa Cordes (HU Berlin), Nico Faltin (HU Berlin) |
| Einführungsvortrag: NLP-Methoden in der Klassischen Philologie (Schwerpunkt: Word Embeddings) | 09:15 - 10:15 Uhr | Dr. Andrea Beyer (HU Berlin), Konstantin Schulz (HU Berlin) |
| Kleine Pause | 10:15 - 10:30 Uhr | |
| Forschungstandem: Blick in die Werkstatt | 10:30 - 11:15 Uhr | Prof. Dr. Thomas Baier (Julius-Maximilians-Universität Würzburg) |
| Kleine Pause | 11:15 - 11:30 Uhr | |
| Forschungstandem: Erfahrungsbericht | 11:30 - 12:15 Uhr | Joshua Burgert (Albert-Ludwigs-Universität Freiburg) |
| Mittagspause | 12:15 – 13:45 Uhr | |
| Hands-On Workshop: Data Preprocessing & Word Embeddings | 13:45 – 15:45 Uhr | Daidalos-Team |
| Pause | 15:45 - 16:30 Uhr | |
| Abschlussdiskussion: NLP-Methoden - eine Revolution für die Literaturwissenschaft in der Klassischen Philologie? | 16:30 – 17:30 Uhr | u. a. mit PD Dr. Monica Berti (Universität Leipzig), Prof. Dr. Lisa Cordes (HU Berlin) |
| Im Anschluss besteht die Möglichkeit zu einem gemeinsamen Abendessen. |
Anreise
Adresse:
Humboldt-Universität zu Berlin
Unter den Linden 6
10117 Berlin
Raum 1066e (Erdgeschoss)
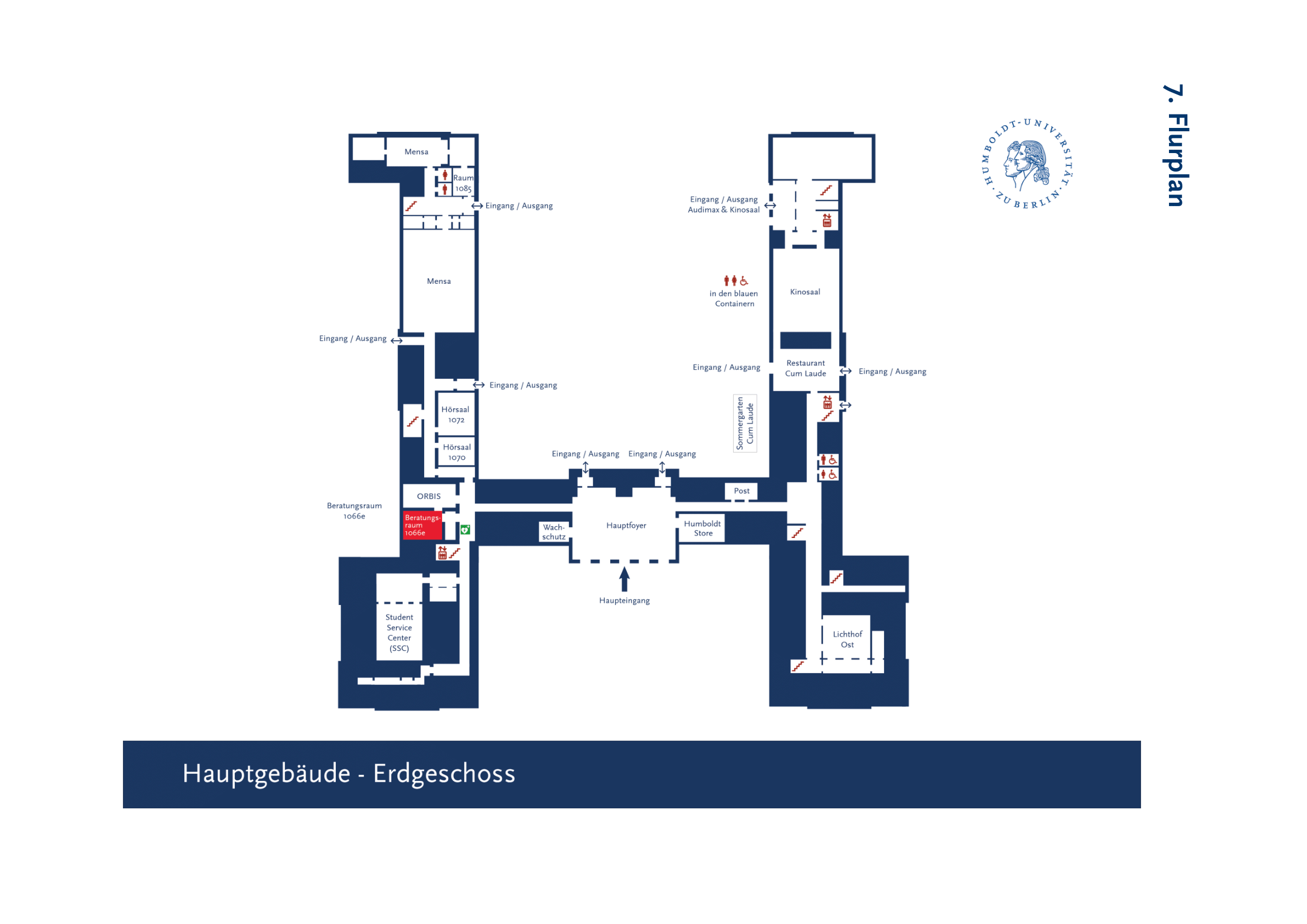
Der Veranstaltungsort ist fußläufig von den Bahnhöfen Friedrichstraße (U6, S1, S3, S5, S7, S75, S9), Unter den Linden (U6, U5) und Museumsinsel (U5) zu erreichen.
Vom Berliner Hauptbahnhof zur Humboldt-Universität
- U5 (Richtung Wuhletal) bis Unter den Linden, von dort 300m Fußweg
Vom Flughafen BER zur Humboldt-Universität
- FEX (Richtung Berlin Hbf) bis Ostkreuz, dort umsteigen in S3, S5, S7, S75, S9 bis Friedrichstraße, von dort 600 m Fußweg
- RE 8 (Richtung Wittenberge/Wismar) bis Friedrichstraße, von dort 600 m Fußweg
- S 9 (Richtung Spandau) bis Friedrichstraße, von dort 600 m Fußweg
- RB 23 (Richtung Potsdam/Golm) bis Friedrichstraße, von dort 600 m Fußweg
PKW - Parken und Anfahrt
- Direkt an der Straße "Unter den Linden" darf nicht geparkt werden. In der näheren Umgebung befinden sich aber verschiedene kostenpflichtige Parkmöglichkeiten, etwa in der Dorotheenstraße und in verschiedenen Tiefgaragen.
- Beachten Sie bitte die in der Innenstadt geltenden Umweltzonen. Die Nichtbeachtung kann ein Bußgeld nach sich ziehen.
| Datum | Veranstaltung | Titel | |
|---|---|---|---|
| 11.11. | Labor für digitale Medien, Uni Kiel | KI im Spracherwerb | |
| 09.09. - 15.09. | Sommer-Uni Berlin | Fach-und Fallspezifische KI-Bildung in den Geisteswissenschaften | |
| 11.07. - 13.07. | Aquilonia, Kiel | Einsatz maschineller Sprachverarbeitung zur automatisierten thematischen Kategorisierung mittellateinischer Bittbriefe an den Papst | |
| 04.07. - 06.07. | Volturnia, KU Eichstätt | Digitale Methoden in der Klassischen Philologie | |
| 01.07. | Tag des Interdisziplinären Zentrums, HU Berlin | Daidalos: NLP-Forschungsinfrastruktur für die Klassische Philologie | |
| 27.06. - 29.06. | Nomina Omina, Leipzig | Daidalos: NER for Literary Studies on Latin and Greek Texts | [PDF] |
| 18.06 | Research Lounge, HU Berlin | Eine NLP-Infrastruktur für KI-skeptische User | [PDF] |
| 14.06. | Daidalos-Workshop, HU Berlin | NLP-Methoden in der Klassischen Philologie - Word Embeddings | [PDF] |
| 05.06. - 07.06. | EUNIS, Athen | Can Jupyter help Daidalos? Or: How to develop and assess Digital Literacies? | [PDF] |
| 02.04. - 05.04. | DAV-Kongress, Wuppertal | Reflexion mit und über KI im AU | [PDF] |
| 16.03. | Fortbildung Thüringen | KI im Lateinunterricht | [PDF] |
| 26.02. - 01.03. | DHD, Passau | Wie viel Methodenkompetenz braucht ein User? | [PDF] |
| 29.01. | Fortbildungstag Abtei-Gymnasium, Köln | Generative KI und ihre Bedeutung für Bewertungskontexte | [PDF] |
| 22.01. | KU Eichstätt, Vorlesung | Digitale Methoden in der Klassischen Philologie | [PDF] |
| 11.01. | DH-Kolloquium, FU | NLP-Infrastruktur für die Klassische Philologie | [PDF] |
| Datum | Veranstaltung | Titel | |
|---|---|---|---|
| 11.10. | Fortbildung DAV Berlin-Brandenburg | @chatbot: warum kannst du latein et quo vadis? | [PDF] |
| 04.10. - 06.10. | Forge 2023, Tübingen | Data Literacy für die Klassische Philologie: dAIdalos – eine interaktive Infrastruktur als Lernangebot | [PDF] |
| 28.09. - 29.09. | Tagung, Freiburg: (Digitale) Chancen für den Lateinunterricht | Digitalgestützte Textanalyse in Forschung und Lehre | [PDF] |
| 28.09. | GI-Tagung Informatik 2023, Berlin | Daidalos: Forschen und Lernen zugleich? Data Literacy als Lernaufgabe für die Klassisch-philologische Forschung | [PDF] |
| 27.09. | Fachtagung Bielefeld: Zwischen Wachstafel und ChatGPT - KI im Lateinunterricht | Vortrag: KI-Bildung: Was, warum und wie? | [PDF] |
| 27.09. | Fachtagung Bielefeld: Zwischen Wachstafel und ChatGPT - KI im Lateinunterricht | Workshop: Mit und über KI-Tools im Lateinunterricht reflektieren | [PDF] |
2024
- Beyer, A. (2024): KI im altsprachlichen Unterricht. Beyer, A. LGNRW, 5(1): i. Vorb.
- Beyer, A. (2024): Rezension zu „KI-Bildung im Lateinunterricht – Ein schulpraktischer Leitfaden“ der Reihe KI-Bildung im Ovid Verlag, Hrsg. Rudolf Henneböhl. Beyer, A. LGBB, 68(2): i. Vorb.
- Beyer, A. & Schulz, K. (2024): Daidalos: Wie viel Methodenkompetenz braucht ein User? https://zenodo.org/records/10698299 (peer-reviewed)
2023
- Daidalos: Forschen und Lernen zugleich? Data Literacy als Lernaufgabe für die Klassisch-philologische Forschung. Beyer, A.; and Schulz, K. In INFORMATIK 2023 - Designing Futures: Zukünfte gestalten, pages 391–393, Berlin, 2023, (peer-reviewed) https://dl.gi.de/server/api/core/bitstreams/54020598-2f57-49e5-997e-1b0cd46bf35f/content
- Data Literacy für die Klassische Philologie - dAIdalos - eine interaktive Infrastruktur als Lernangebot. Beyer, A.; and Schulz, K. In FORGE 2023 - Anything Goes?! Forschungsdaten in den Geisteswissenschaften - kritisch betrachtet, pages 143–146, Tübingen, 2023, (peer-reviewed). https://zenodo.org/records/8386450